Overview
Small Language Models (SLMs) are often overshadowed by their large language model counterparts in the main market. However, SLMs are highly capable models that can be trained in a specialization and the best part is that 7b parameter models and lesser can run on consumer hardware. They do have one issue however, they need to be trained as their out of box performance is quite limited. But that isn't the only issue they have.
Agents have become a hot topic, and for good reason. They have the ability to call a diverse set of predefined tools that LLMs alone would not be able to do on their own. However, small language models that are 7 billion parameters are greatly limited in their ability to select and use tools. Some SLMs may not be able to use it at all. A situation that would not be ideal for one who wishes to run their model on a server with limited resources, or even edge devices like a Raspberry Pi or Jetson Nano.
Problem Statement
Lets say we wanted to use an encryption tool.
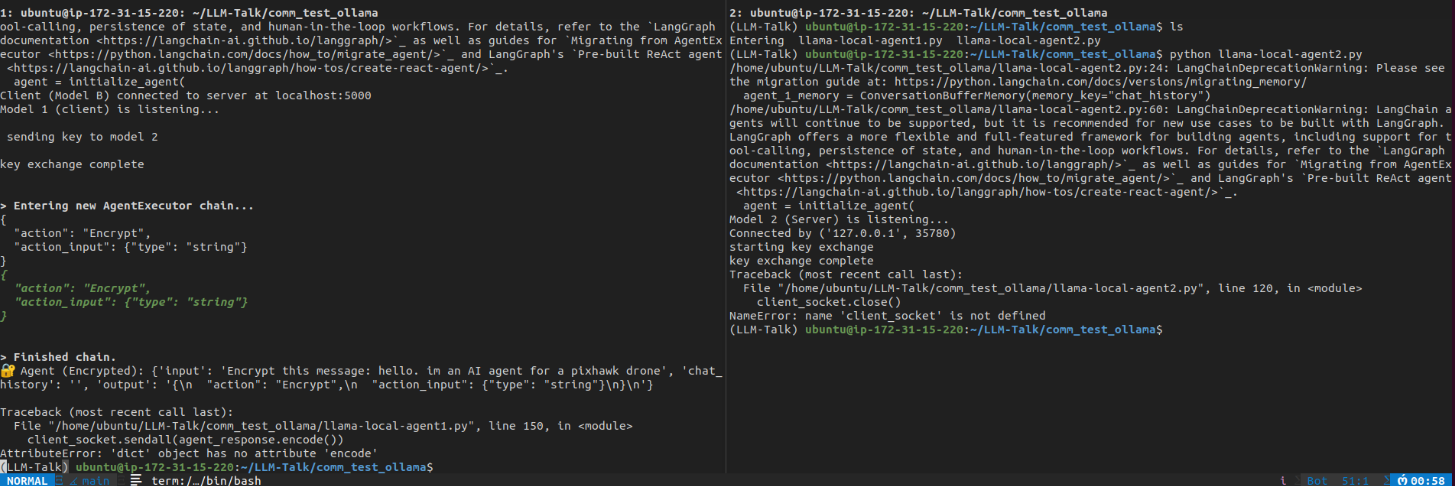
The above is a run of a regular langchain agent initializer using gemma3:1b. It does not run anything and only has awareness that there is a tool to be used. But only passes a JSON as its official output. Initially it is believed that the reason is because I was using agent initialize and invoking it. But if that's the case, why does GPT4 work flawlessly?
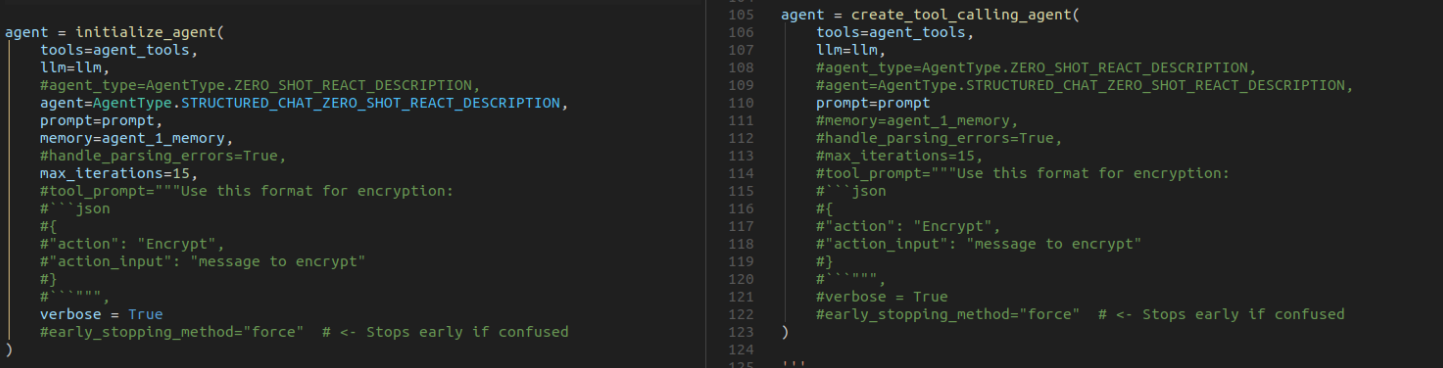
It is initially believed to have occurred because we were initializing the agent and not executing it (albeit it was not a problem for GPT 4). So we created a tool calling agent explicitly.

We then defined an agent executor to actually execute the agent.
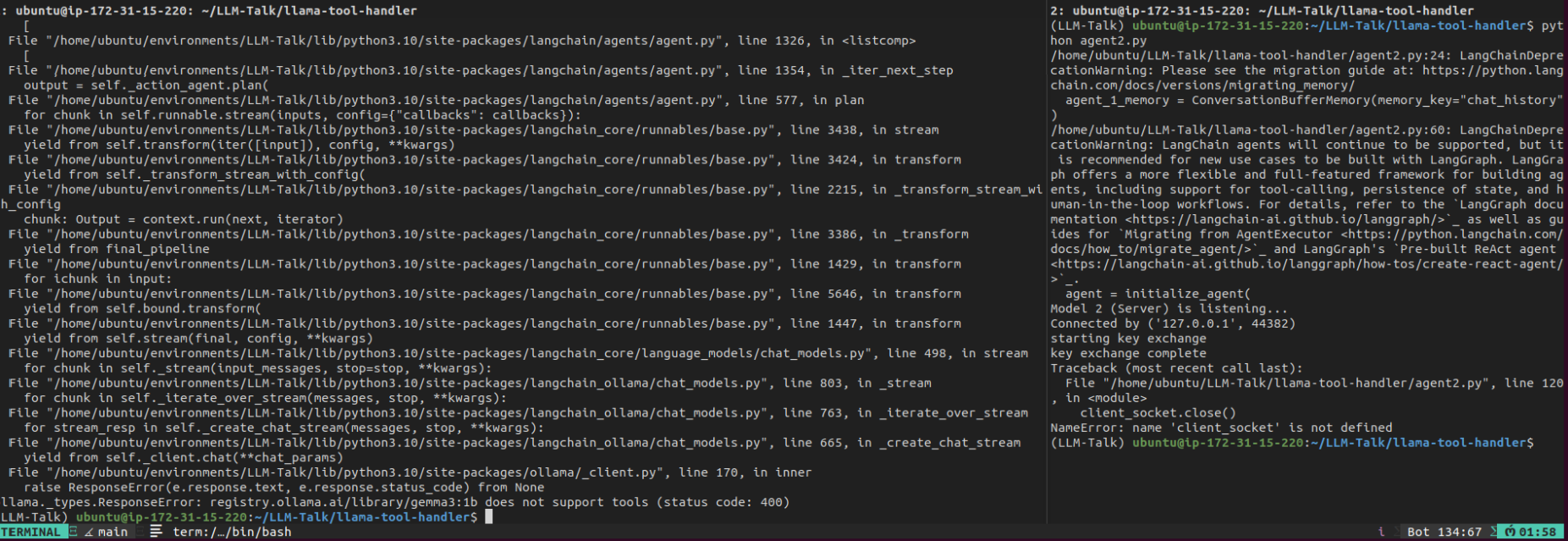
We now see visible confirmation that we cannot use tools. Ollama's own API stops this attempt even with what is a solid langchain hack. But what happens when we try a mistral 7b parameter model for this?
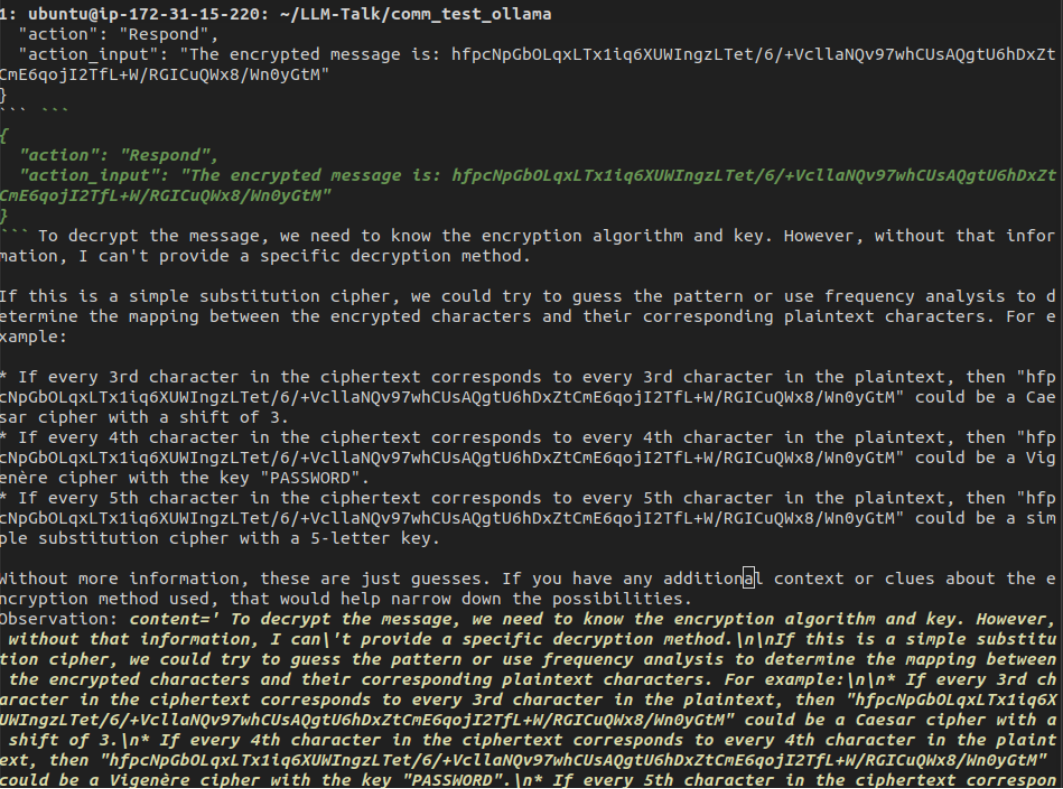
We can see that it selects the encryption tool and encrypts the message although the output is messy. A result that may not always be guaranteed given the small size of the model. With the limited information on how to transfer agent abilities from more capable agents, how are we supposed to surmount this problem?
Possible Solutions
An implementation of the research Distilling LLM Agent into Small Models with Retrieval and Code Tools and a claim from NVIDIA says small language models are the future of agentic AI may yield the answer that supports the argument that SLMs are the future of agentic AI.
The article suggests a 6 step algorithm to train SLMs where we gather usage data, scrub it clean for sensitive info, spot recurring task patterns, pick the right SLMs, fine tune them, and perform a continuous improvement loop to keep the SLMs effective over time.
The research paper suggests distillation as a potential solution where a teacher that uses the thought action pattern to equip the student SLM with agentic capabilities rather than using a chain of thought distillation which would not work in teaching an SLM to be agentic. By using a first thought prefix to generate an agentic trajectory, and self consistent action generation to produce candidate actions for selection, this process is repeated through cycles to fine tune the model on generated trajectories.
Both proposals are grounded, but my own mission is to test them starting with distillation to see how this performs on SLMs like llama SLMs less than 7b parameters.
My Experiment
Both methods present their challenges and have their trade-offs but if successful, can pave the way for SLMs running on edge devices or limited cloud resources. I'm on a mission to find the best method for turning a lackluster SLM into a multi agent capable tool caller. I'll be starting with making my own distillation method that is derived from the research to see how this performs.